
Selenium provides different type of locators to uniquely identify web elements on the browser.
Any web application elements that render on the HTML DOM [tags & attributes] can be automated using selenium.
To view the HTML DOM on any browser –
On any browser > load the application url > right click on any element > Inspect [to get the tags / attributes to locate]
Selenium available locators –
by id
Selenium can identify the elements based on the HTML id attribute – By.id(String str)
Site – qavalidation.com/demo
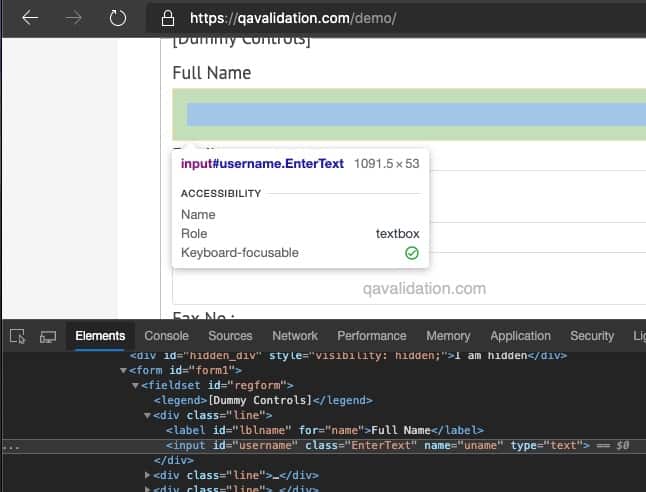
On the Full Name text box > right click > Inspect
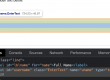
HTML DOM for the Full Name field –
<div class="line"> <label id="lblname" for="name">Full Name</label> <input id="username" class="EnterText" name="uname" type="text"> </div>
WebElement txt_uname = driver.findelement(By.id("email"));
txt_uname.sendKeys("qav box");
or
By locator = By.id("email");
driver.findelement(locator).sendKeys("qav box");
by name
Selenium can identify the elements based on the HTML name attribute – By.name(String str)
In the same above screenshot / example, we can even identify the User Name field using the name attribute
WebElement txt_uname = driver.findelement(By.name("uname"));
txt_uname.sendKeys("qav box");
or
By locator = By.name("uname");
driver.findelement(locator).sendKeys("qav box");
Note – sometimes, more than one field / browser element can have same same name
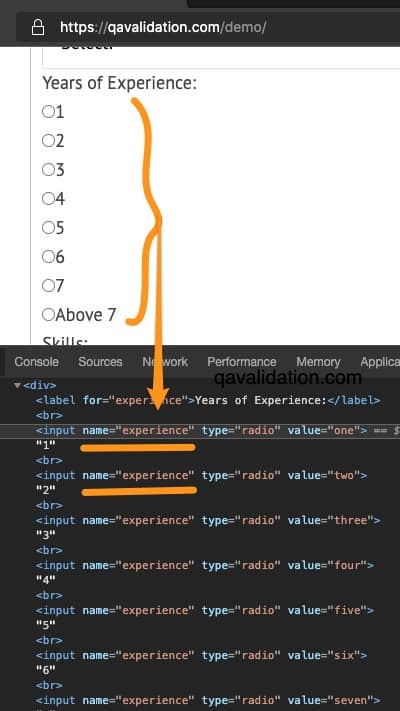
For example – Radio buttons
All the radio buttons will have the same name, as you can see all the below buttons below has name = experience, in this case you need to use some other attribute to identify the specific button you want to click or perform any action.
You can use xpath locator and use the attribute value = ‘one’ for 1st radio button or value = ‘two’ for 2nd radio button and so on.. [you will learn use of xpath in a moment / scroll down to xpath section to know more]
by className
Selenium can identify the elements based on the HTML class attribute – By.className(String str)
On the image 1 – you can see the HTML for User Name field do have a class attribute [class = EnterText“]
And in selenium we can identify the element as –
WebElement txt_uname = driver.findelement(By.className("EnterText"));
txt_uname.sendKeys("qav box");
or
By locator = By.className("EnterText");
driver.findelement(locator).sendKeys("qav box");
Note –
class name is normally not unique across the screen, you might get no. of elements matching with same class name, so make sure you have unique class name for the element you want to perform action.
by linkText
Selenium can identify the elements based on the HTML class attribute – By.linkText(String str)
Site – qavalidation.com/demo
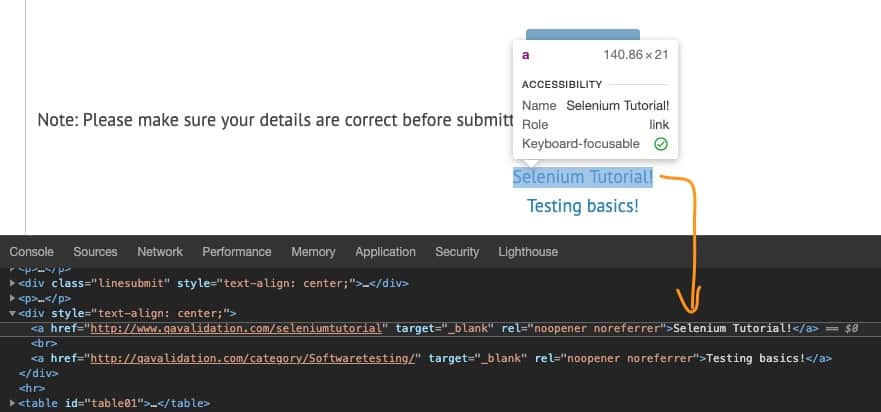
On the link text selenium tutorial > right click > Inspect
HTML DOM for the selenium tutorial link –
<div style="text-align: center;">
<a href="http://www.qavalidation.com/seleniumtutorial" target="_blank" rel="noopener noreferrer">
Selenium Tutorial!</a>
<br>
<a href="http://qavalidation.com/category/Softwaretesting/" target="_blank" rel="noopener noreferrer">
Testing basics!</a>
</div>
linkText – the name given to the ‘a’ tag in the html content.
And in selenium we can identify the element as –
WebElement selLink = driver.findelement(By.linkText("selenium tutorial"));
selLink.click();
or
By locator = By.linkText("selenium tutorial");
driver.findelement(locator).click();
by partialLinkText
There is another locator partialLinkText where you can use part of link text to identify the link, if the string matches to any of the link text on the screen, it will perform the action
for example –
WebElement selLink = driver.findelement(By.partialLinkText("selenium tut"));
selLink.click();
or
By locator = By.partialLinkText("selenium tut");
driver.findelement(locator).click();
If two links with the same text are present, then the first match will be used to perform the action.
by tagName:
Selenium provides a way to identify the element based on the tag name from the HTML DOM
In the below screenshot, you can see the tagname as “legend“, which is unique to the application screen
But be carefull when you use the tagName locator, as most of chances you will get no. of elements, but we have find a way to locate element uniquely.
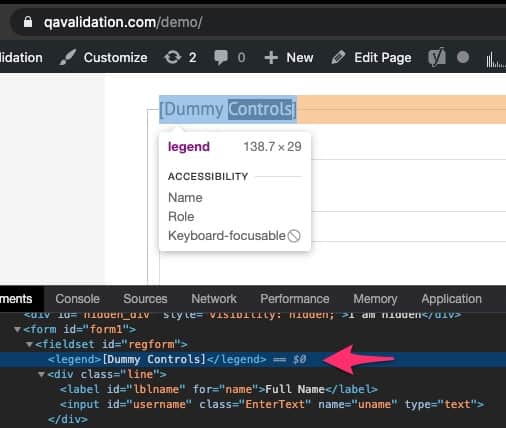
so for the element legend, you can locate as
WebElement legendLocator = driver.findelement(By.tagName("legend"));
In some cases you might need to find only links of screen, then you can use the tagName as “a” or like that.
then you can use the selenium’s findelements method instead of findelement
findelements() returns multiple elements based on the locator specified, where as findelement() returns the first occurrence of element if more elements are matched.
so to get all the links on screen, you can use
List<WebElement> pageLinks = driver.findelements(By.tagName("a"));
by xpath:
XPath is the language used for locating nodes in an XML document and HTML can be an implementation of XML (XHTML).
Selenium opens up all sorts of new possibilities such as locating the third checkbox on the page.
XPath locators can also be used to specify elements via attributes other than id and name.
Example – on the Site – qavalidation.com/demo, Let’s find the Skills label using xpath
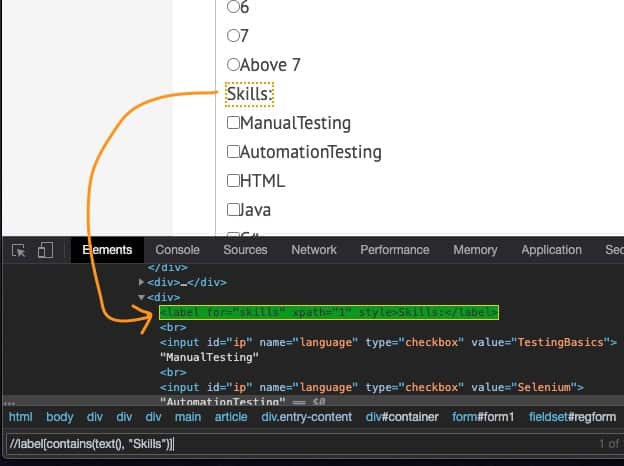
WebElement Skills = driver.findelement(By.xpath("//label[@for='skills']"));
by CSS Selector:
CSS (Cascading Style Sheets) is a language for describing the rendering of HTML and XML documents.
CSS uses Selectors for binding style properties to elements in the document.
let’s see how we can derive the css selectors from the html content:
css=tag#id
css=tag.class
css=tag[attribute=value]
css=tag.class[attribute=value]
css=tag:contains(“inner text”)
Note: inner text is the exact word that is displayed on browser for that element.
Example – on the Site – qavalidation.com/demo, Let’s find the Skills label using css selector
WebElement Skills = driver.findelement(By.cssSelector("label[for='skills']"));
Note:
ID identifies faster than other locators, but some times we will not have ID attribute for each element, so it’s more flexible to use XPATH / CSS Selector.
Order of preference – id > css selector > xpath > rest follows
For more details about xpath & css selector and how to dynamically identify elements, refer xpath & css selector patterns
6 Comments