In one of our previous post selenium locator strategies, we have learned how to identify elements based on HTML tags or attributes.
In this post, mostly we will be talking about the key differences between XPATH & CSS Selector, their patterns to locate browser elements.
Patterns are basically the syntaxes we will use to identify single / multiple / dynamic elements.
NOTE: Refer Absolute and Relative XPATH for xpath types.
Key differences between Xpath & CSS Selector –
| Xpath | CSS Selector |
| Bidirectional You can traverse parent to child and child to parent on DOM E.g – following-sibling, preceding-sibling | Unidirectional You can traverse only parent to child, but not vice versa E.g – label[id=’lblname’] ~ input Fetch all the input elements of id=lblname |
| Slower in performance | Faster in performance / to locate element |
| Can identify element[s] based on the text E.g – //T[contains(text(), ‘someText’)] | Not possible |
| Compatible with most older browsers / versions | Good support for newer / modern browsers |
| Has Xpath axes to locate element[s]. E.g – //div[@id=’apple’]/ancestor::div Fetch all the parent/grandparent elements of id=’apple’ | Attribute based locator identification. E.g – #fruits – for id=fruits .cars – for class=cars |
| Xpath is used to locate XML and HTML documents. | CSS Selector is used to locate only HTML documents. |
| More options to locate element[s], need learning curve | Easy to understand, but not many options to locate elements |
For the XPATH axes, refer https://www.w3schools.com/xml/xpath_axes.asp
Patterns –
Notation –
T – TagName or element
A – Attribute
V – Value
| XPATH | CSS Selector | Description |
| //T[@A=’V’] | T[A=’V’] | |
| //*[@A = ‘V’] | [A = ‘V’] | |
| //T[@A] | T[@A] | |
| //T/T1 | T > T1 | |
| //T//T1 | T T1 | |
| //T[@A= ‘V’][@A1= ‘V1’] | T[A= ‘V’][A1= ‘V1’] | and operator |
| T[A=’V’ or A1=’V1′] | T[A=’V’],[A1=’V1′] | or operator |
| //T[contains(@A, ‘V’)] | T[A*= ‘V’] | contains |
| //T[contains(text(), ‘V’)] | ||
| //T[starts-with(@A, ‘V’)] | T[A^= ‘V’] | starts-with |
| //tagName[ends-with(@attribute, ‘value’)] | tagName[attribute$=’value’] | ends-with |
| # – element with id | CSS with id – Input#username | |
| . – element with class | CSS with classname – Input.uname | |
| .//table[@id=’table01′]//tr[2]//td[2] | #table01 tr:nth-child(2) td:nth-child(2) or table[@id=’table01′].2.2 | |
| //label[@id=’lblname’]/following-sibling::input or //label[@id=’lblname’]/following-sibling::input[1] | label[id=’lblname’] + input or label[id=’lblname’] + * | Will identify the 1st occurrence of input adjacent to label field |
| //label[@id=’lblname’]//following-sibling::input | label[id=’lblname’] ~ input | Will identify all the input elements adjacent to label field |
| //input[@id=’username’]/preceding-sibling::label |
Element with attribute(A) with value (V) :
Any element on the DOM having attrbute-A with Value-V irrespective of the element type
xpath: //*[@A = 'V']
CSS: [A = 'V']
With tag name(T) and attribute(A) with out value(V):
All the Elements-T with attribute-A, doesn’t matter what is the attribute value
xpath: //T[@A]
CSS: T[A]
With tag name(T) and attribute(A) with value(V):
Element-T having attribute-A with value-V
xpath: //T[@A= 'V']
//T[@A= 'V'][@A1= 'V1']
CSS: T[A= 'V']
T[A= 'V'][A1= 'V1']
xpath: //T[contains(@A, 'V')] or //T[contains(text(), 'V')]
CSS: T[A*= 'V']
xpath: //T[starts-with(@A, 'V')] or //T[starts-with(@A, 'V')]
CSS: T[A^= 'V']
Example:

Navigate to this demo site
We can use any of the following xpath to identify the FullName text field
xpath: //input[@id='username'][name='uname']
CSS selector shortcuts for class or id attributes
For elements with id
css : #
e.g - input#username
For elements with class
css: .
e.g - input.commit
Identify input tag (element) with both id and name attribute
xpath: //input[@id='username' or name='uname']
Note: identify input tag (element) with either id or name attribute that matches.
If we find xpath with //input[type='text'], then may be getting no. of text boxes on the page and selenium may be confusing which one to act upon.
If the attribute value changes partially each time we navigate to page, that time//input[contains(@id,'usern')] //partial attribute value
let’s say, on the same page, we need to identify the link “Testing Basics!” and can’t remember whole text,
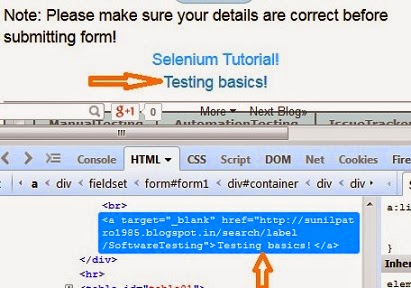
then we can use – //a[contains(text() , 'Testing')]
Note: text is not an attribute, so mentioned as method without @, this will search all the links on the web page with link text contains the word Testing.
following-sibling
Visit this demo site – https://qavbox.github.io/demo/listitems/
<ul id="mygroup">
<li> List Item 1
<ul id="subgroup">
<li> Sub list 1 </li>
</ul>
</li>
<li> List Item 2</li>
<li> List Item 3</li>
<li> List Item 4</li>
</ul>
<p > Paragraph 1 </p>
<p > Paragraph 2 </p>
<p > Paragraph 3 </p>
<p > Paragraph 4 </p>
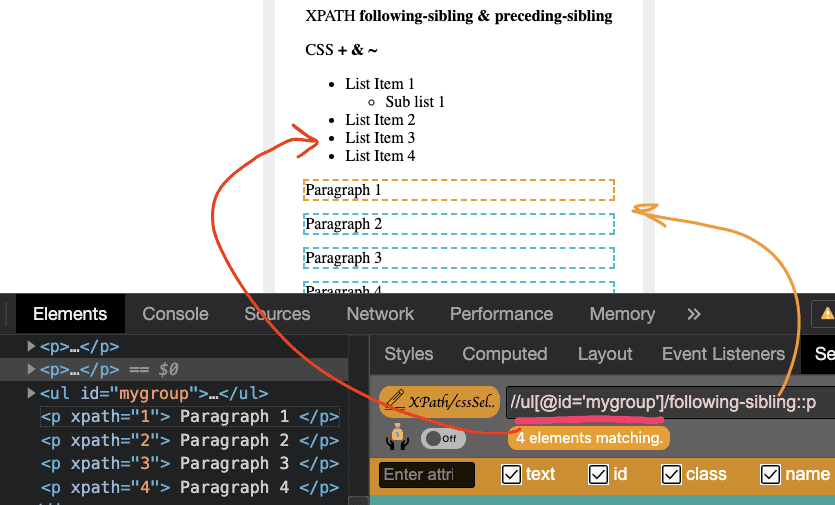
From the above screenshot, we can identify the ul using id=”mygroup”, but the paragraphs can’t be identified,
as ul & p tags are siblings, so we can use following-sibling to identify the paragrapths
driver.findelements(by.xpath("//ul[@id='mygroup']/following-sibling::p"));
or //ul[@id='mygroup']/following-sibling::p[1]
p[1] – will identify the 1st occurrence of paragraph
preceding-sibling
In the sibling, matched element before to the current element
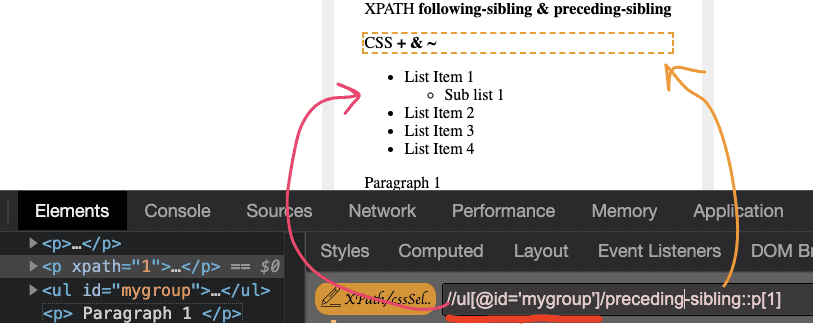
driver.findelement(by.xpath("//ul[@id='mygroup']/preceding-sibling::p[1]"));
xpath with table:
on the demo site
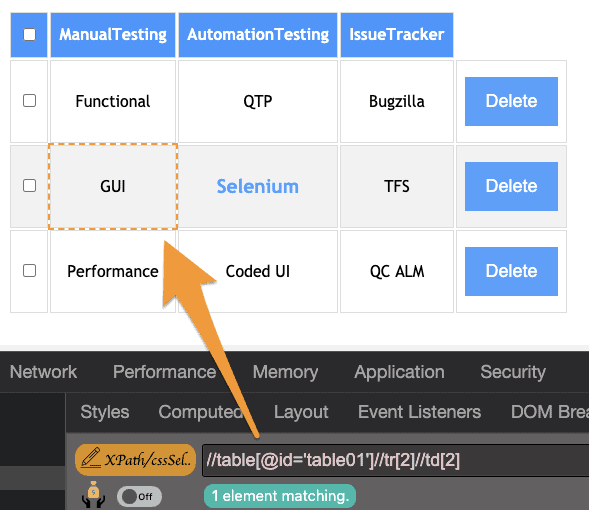
To access the 2nd row and 2nd column data: i.e value is GUI from the above tablexpath: //table[@id='table01']//tr[2]//td[2]
css: #table01 tr:nth-child(2) td:nth-child(2)
To check the elements that are disabled on the web page
driver.findelements(By.xpath("//input[@disabled]"); //input[not(@disabled)]"
driver.findelements(By.cssselector("input:disabled"); //"input:enabled"
To find elements (radio buttons or check boxes) that are checked
driver.findelements(By.xpath("//input[@checked]");
driver.findelements(By.cssselector("input:checked");
InnerText and TextContent
driver.findelement(By.xpath("//input[innertext='value']"));
or
driver.findelement(By.xpath("//td[textcontent='value']"));
4 Comments